I let my promotion with tenure (Librarian II at my institution) pass without comment last year because it was a dreadful year in which some of my colleagues lost jobs and I felt more than ever like I had won some kind of a lottery just by happening to be in the right place at the right time. With that said, though, I know a lot of work goes into evaluating tenure cases, and I am grateful to my Rutgers colleagues and to my external referees for their careful attention and support. I also felt the need to share some of what went into my dossier, because I know how hard it is to articulate one’s value in a newer academic library role. I am the first digital humanities librarian at my institution and I am also subject librarian. I was acutely aware that DH looks a bit different at every institution and I was perhaps overly sensitive about the gaps in my own portfolio vis-à-vis whatever shared understanding of digital humanities could be said to exist. It was a profound help to me to be able to read other people’s professional statements as I was preparing my own, including those of Heather Coates and Ryan Cordell. Huge props also to Kalani Craig for publishing her statement after she submitted (and before hearing the result!). So with this post, I would like to share my own personal statement, in case others can benefit from seeing how I made sense of the various threads of my professional responsibilities.
It may help to preface this with the gap that concerned me the most. Project development or management is often among the more highly prized skills of digital humanities librarians. Due to the way my job is configured, and the way digital infrastructure works at my institution, I could not get too heavily involved in the management of collaborative digital research projects. I can consult, and I can train, but I often cannot be the one to manage the day-to-day and week-to-week labor of these projects, as this kind of work is extremely time-intensive, and, like more and more of us, I juggle many roles at my institution. And while I may have some misgivings about this fact, I am also grateful of the chance to consult on several smaller digital projects, and to develop a few of my own, which have become opportunities for the mentorship of student scholars interested in digital methods. Although it has taken me a while to settle into this truth, there is no one way of doing the job of a digital humanities librarian. We rely on our own professional interests and strengths, and the needs and interests of those with whom we regularly work, to shape our paths.
Personal statement, submitted August 9, 2019
Librarianship
My greatest aim as a hybrid librarian active in digital humanities and subject liaison work is to bring both sides of my librarianship work into constructive, mutually beneficial dialogue, with the goal of reinvigorating public services librarianship through a critical understanding of twenty-first century challenges like authority, information overload, and intellectual property. As the first person to occupy the role of digital humanities librarian at Rutgers–New Brunswick, my work has contributed to many firsts for the Libraries. My interpretation of digital humanities librarianship emphasizes 1) fostering opportunities to learn diverse digital methods that will improve research and teaching, and 2) creating a community of practice in which experts on campus can connect and collaborate with each other. Defining digital humanities as the use of digital tools and methods to study the humanities, I have used my musical background as a disciplinary lens through which to communicate a range of research activities, such as the capture, creation, enrichment, analysis, and interpretation of data. At the same time, I possess the language expertise required to be a subject liaison in Comparative Literature, French, and Italian, and I have found many fruitful points of contact between my subject and functional library roles.
My activity as a digital humanities librarian focuses to a great extent on pedagogy. I am one of few librarians or technologists at Rutgers who collaborate with disciplinary faculty to deliver lectures and trainings on digital research methods in term courses at the graduate and undergraduate levels; I have created original material for courses in the fields of literature, history, musicology, and Latino and Caribbean studies. Humanities faculty interested in exploring digital humanities in partnership with a librarian constitute a new audience for the Libraries. I plan, organize, and teach stand-alone workshops in the libraries on the sources and methods of digital humanities in order to create and grow collaborations. These workshops have attracted broad participation from over 30 academic departments and programs in the humanities, the social sciences, and the sciences. Via these embedded and stand-alone workshops and lectures, I have reached nearly 1,500 students and faculty in the past five years. I teach a Byrne seminar called “Data Mining in the Humanities” that introduces digital humanities to first-year undergraduates; the syllabus, deposited in the Big Ten DH group of Humanities Commons, has been downloaded over 200 times. I continue to develop my personal digital skill set, which includes humanistic applications of XML technologies, statistical programming, and Geographic Information Systems, through regular attendance of workshops, courses, and intensive summer institutes. As a result of my work, I was invited by faculty of the English department to help develop a new 300-level, team-taught course called “Data and Culture,” scheduled to be taught in 2020-21, that will provide a broad theoretical and practical overview of various topics in digital culture. I was also invited by senior administrators in Rutgers Global and the School of Arts and Sciences (SAS) Honors Program to develop a two-week seminar in Spain on the topic of text encoding and manuscript studies for the summer of 2020.
Digital humanities community building and research infrastructure inform my work on several library task forces and working groups. I helped launch, and I currently oversee the Digital Humanities Lab in Alexander Library, a cross-disciplinary research space supported by the Libraries and the School of Arts and Sciences, where students, faculty and staff meet to work on projects and learn about digital methods. I have served as chair and a member of the system-wide Libraries Digital Humanities Working Group. My work with this group involved the development of a Libraries-hosted digital publishing service that allows scholars to use WordPress and Omeka for course projects and the sharing of informal research; this service has been used by over 200 faculty and students across New Brunswick, Newark, and Camden. As a steering member of the Libraries’ Graduate Specialist program, in which graduate students supplement library-based consulting and training in advanced digital research methods, I supervise the work of a digital humanities graduate specialist who provides specialized assistance in text analysis methodologies using the R programming language. Together with graduate student conveners, I hosted a digital humanities reading group, running in Fall 2017, in which a core group of participants from across the humanities and social sciences explored the topic from a variety of perspectives including race and gender theory, pedagogy, and digital project development. I work with the Geography department, and the Rutgers Undergraduate Geography Society, among others, to host an annual mapathon in which participants contribute geospatial data to the Humanitarian OpenStreetMap platform to aid disaster relief efforts around the globe. I have sought to further the libraries’ important role in advanced research through my service as leader of the Research Spaces team, which studied specialized research spaces in academic library settings, and as a current member of the Research Data Services, Digital Projects, and Copyright teams.
As part of my liaison duties, I have met with faculty and graduate students in Classics, Comparative Literature, French, and Italian to discuss scholarly communication topics, such as open access, self-archiving, digital publishing, and author rights in their individual disciplines. We have discussed Scholarly Open Access at Rutgers (SOAR), the interface for depositing scholarly articles, and the relaunch or conversion of several departmental journals to a new digital platform. I have helped contacts in Art History, Comparative Literature, and Italian to transition their graduate student journals to the user-friendly WordPress platform, thereby facilitating the onboarding process for new student editors, extending the longevity of the publications, and providing a venue in which to practice digital publishing skills (see Digital Projects: Project Consultant and Trainer section of CV). I have advised graduate students in my liaison areas and in other departments on the creation of digital projects related to their doctoral research, and on secondary topics of interest, and I have helped these students to acquire new skills, develop their research agendas, and in a few cases start careers in digital humanities. Influenced in some part by my work with their graduate students, the Italian department has sought to expand their involvement in digital humanities by offering DH mini-seminars, taught by visiting professors, and by hiring a DH post-doctoral fellow.
I manage the collections for the departments of Classics, French, and Italian, and the program in Comparative Literature, in consulation with the faculty and graduate students of those disciplines, and I have applied data analysis skills acquired through my research activity to analyze library patron preferences in support of collection management work. For example, by analyzing logs of requests for interlibrary loan books, I discovered a high number of requests for books about digital humanities, as a result, I successfully argued for the creation of a special fund code for the acquisition of monographs in this area. Through similar analyses of requests for literature and literary criticism, I found a high volume of requests for public domain authors like Shakespeare, Virgil, and Euripides, whose texts are freely available online, indicating most likely that Rutgers users are requesting specific editions and translations, or they prefer the print medium for more immersive, cognitively demanding reading. This has, in turn, influenced my selective uptake of e-books in the humanities. I have developed and created subject-specific research guides in all of my liaison areas. I also help students conducting multilingual research to navigate the Libraries’ collections, external web resources, and citation styles and tools. In spite of a difficult environment for collection development at Rutgers, I have been able to make strategic additions to our film, monograph, and serials collections, providing enhancements in the areas of Francophone Caribbean and African literature and culture, French Early Modern literature, migration studies, Italian women writers, history of science, and ecocriticism and environmental humanities.
I participate weekly or biweekly in all forms of library public services, including chat, email, and desk reference at Alexander Library. In addition to delivering information literacy instruction in my liaison departments, I also teach library sessions for the Honors College, the SAS Honors Program, and the Rutgers Writing Program.
As a digital humanities librarian and subject specialist, I provide research expertise across multiple domains. I look forward to developing new collaborations in support of cross-disciplinary computational research, including one with the Rutgers Office of Advanced Research Computing (OARC), and to my continued work on the above-mentioned pedagogy projects with the School of Arts and Sciences.
Scholarship
In my scholarship, I pursue topics at the intersections of information studies, digital humanities, and music in support of the activities of emerging interdisciplinary research communities. Applications of computing in music and sound studies are relatively rare, and often challenging because of the non-textual nature of most music information. My work aims to improve the dissemination of high-quality digital research outputs in music, broaden awareness of digital methods in the humanities more generally, and develop frameworks for the evaluation of such resources, with the goal of facilitating new, cross-disciplinary modes of inquiry. Across these topics, I seek to bring newer and established media into critical dialogue with each other by discussing how, for example, social media data can inform the digital preservation programs of archival collections, and demonstrating how the study of manuscripts and print culture can be enhanced by data modeling and the creation of online scholarly editions. In keeping with the interdisciplinary nature of my research, I have been cited by scholars in the fields of music business, music technology, science and technology studies, computer science, and literary studies. The open access versions of my work in RUcore, the Rutgers institutional repository, have been downloaded 200 times by researchers in 20 countries. My research intervention is twofold: advocacy for researcher training that includes material and theoretical engagements with technology, and documentation of the evolving nature of library work in connection with digital humanities research and teaching.
I take a particular interest in non-textual formats that are underutilized (as measured in citations) when compared to other library and archival sources, and have devoted a portion of my research activity to exploring the impact of digital sound recordings among researchers and the general public. I published an empirical study (A Twitter Case Study for Assessing Digital Sound) on the interactions of Twitter users with digital archival sound in the Journal of the Association for Information Science and Technology, a first quartile journal in information science (source: Scimago), and among the top three publication venues for information school faculty. My study characterized a range of user interactions that pointed to impact that was not captured in the citation record. Since communicating the benefits of digitization programs is a sine qua non of successful funding at cultural heritage institutions, I sought with this study to model an approach to the capture and analysis of social media data that could be adapted by researchers with similar objectives.
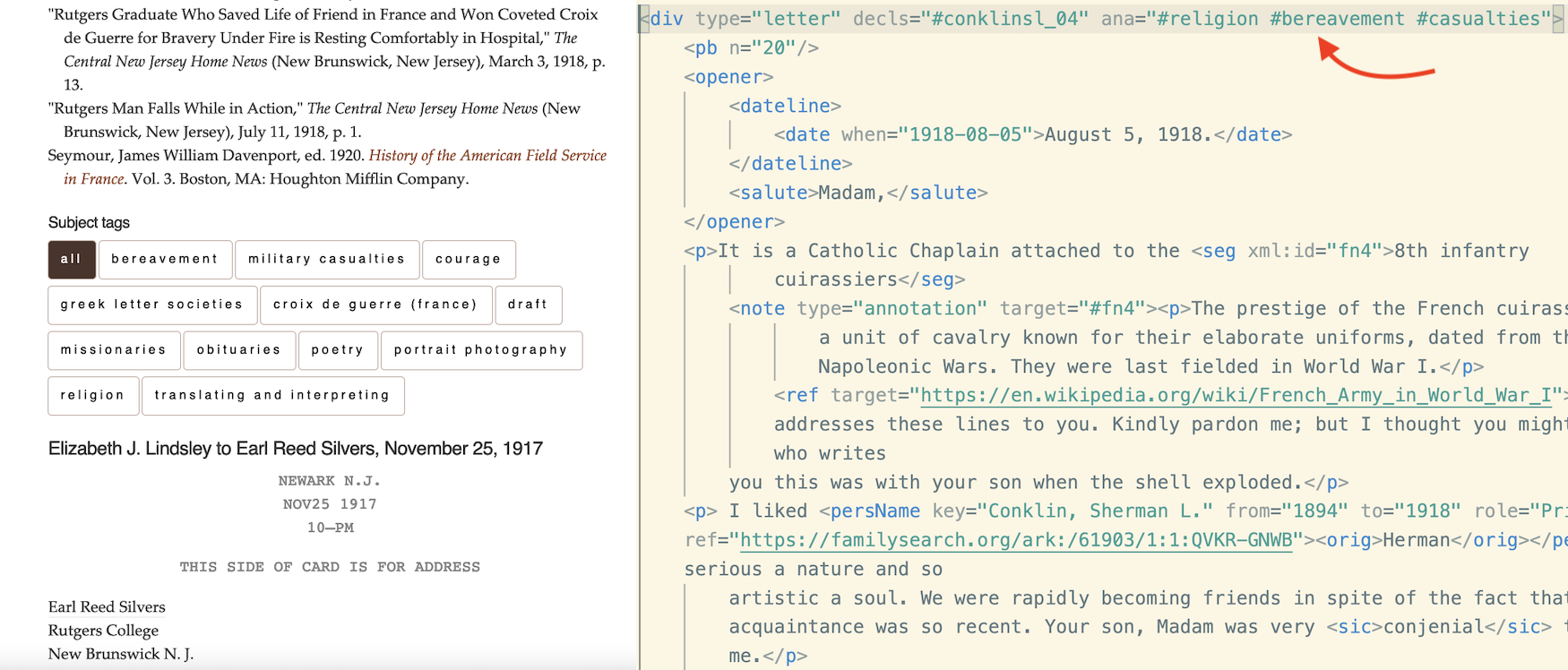
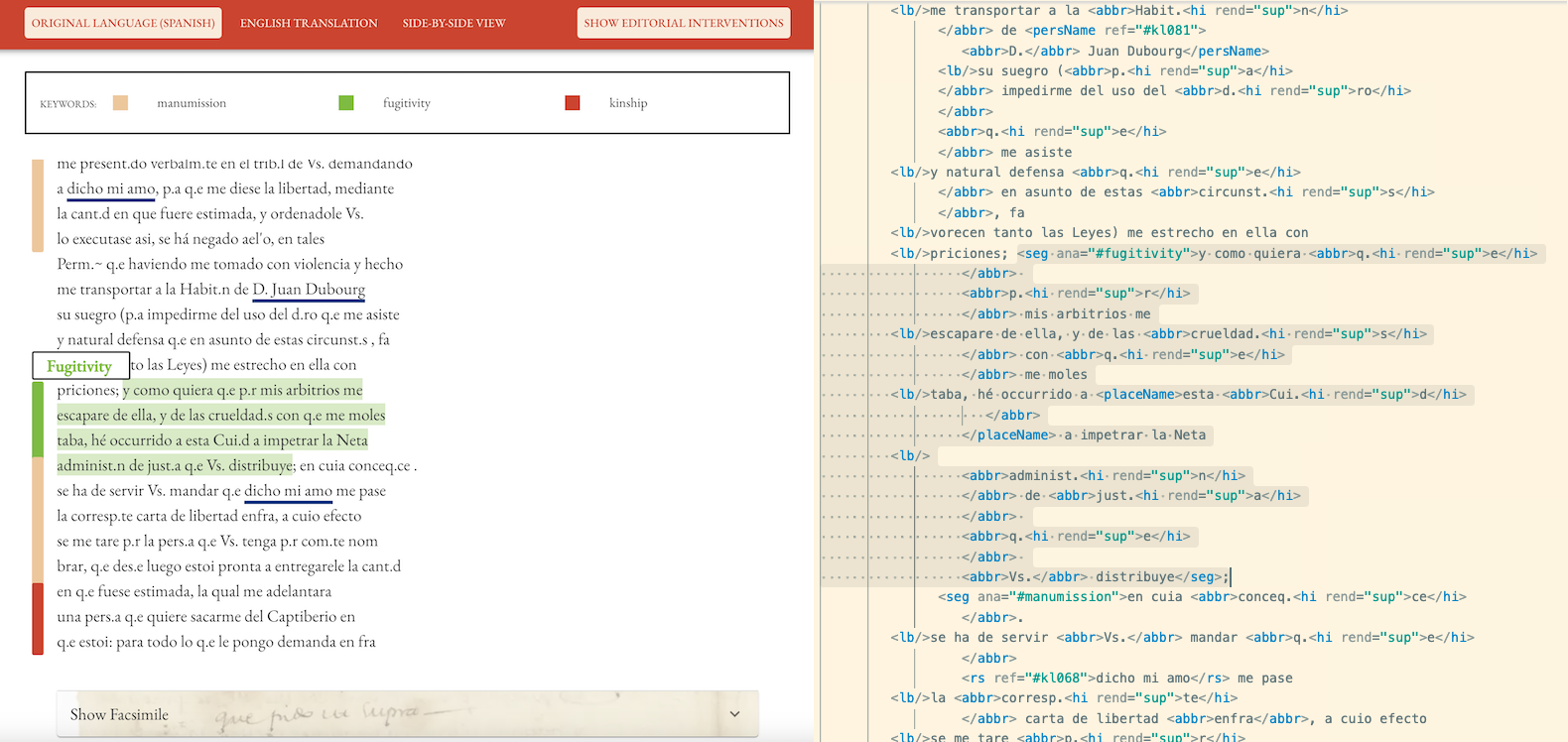
I am committed to the inclusion of digital methods in the education and professional development of students, faculty, and librarians. A thread of my research deals with the subject of digital humanities pedagogy and the introduction of digital methods and tools. My article, “Against the Grain: Reading for the Challenges of Collaborative DH Pedagogy,” published in College and Undergraduate Libraries, describes the common challenges of collaborative digital humanities pedagogy with the purpose of building a foundation of shared knowledge upon which DH practitioners can build. In a post published in the dh+lib Review, Rebecca Dowson of Simon Fraser University wrote of this article, “as Giannetti points out, critical reflections on the challenges of this work have not yet been a focus of scholarship. This gap in the literature is a shame… I hope others will take up Giannetti’s call to share our failures with each other…” This article was recently republished in a monograph entitled The Digital Humanities: Implications for Librarians, Libraries, and Librarianship. My article on text markup, data modeling, and pedagogy (“‘So near while apart’: Correspondence Editions as Critical Library Pedagogy and Digital Humanities Methodology,”) was recently published in the Journal of Academic Librarianship. In this article, I present two case studies on the pedagogical applications of the Text Encoding Initiative (TEI), and the value of librarian involvement in the process and products of TEI editorial work. As a pedagogical exercise, text encoding is an especially compelling way of introducing students to topics such as editorial theory and digital remediation, and librarians have unique knowledge of their collections the technical skills to make such pedagogical interventions successful introductions to the use of primary sources in historical and cultural research.
With colleagues at institutions in the U.S. and the U.K., I am developing a digital research environment called Music Scholarship Online (MuSO), a contributing node of the Advanced Research Consortium (ARC) at Texas A&M University whose aims are to improve discovery of digital scholarly outputs in music as well as develop a peer review framework for the evaluation of digital work in musicology. Our case study entitled “Music Scholarship Online (MuSO): A Research Environment for a More Democratic Digital Musicology” discusses the problems of a closed canon, the underutilized potential of the digital medium, a reward system tied to print publication, and siloed research communities that continue to impact the adoption of digital research methods in musicology. This article was published in Digital Humanities Quarterly, an open-access, peer-reviewed journal covering all aspects of digital media in the humanities. In this article, we outline the ways in which MuSO plans to improve the dissemination of digital outputs in music, and thereby strengthen community standards in music representation, promote data reuse, and create possibilities for new research that expands the musicological discipline. As the MuSO project team pursues additional digital aggregation projects and forms an editorial board to implement standards of digital peer review, I am studying musical genre and form tags as a music-specific method of information retrieval in big digital libraries and databases. As part of this work, I have undertaken qualitative research on the information-seeking preferences of music scholars to develop a holistic model of musical genre for MuSO. In support of this work, I received a fellowship from the Center for Cultural Analysis at Rutgers–New Brunswick to participate in their 2018-19 Classification Seminar.
I present at national and international conferences, and I publish my work in a variety of open access venues and repositories in order to expand the visibility of my research. As an example, on the basis of a conference talk at the joint International Association for Music Libraries/International Musicological Society Congress, which I subsequently published on my blog, I was invited to submit an article (“A Review of Network Approaches in Music Studies”) introducing humanistic applications of social network analysis, published in Music Reference Services Quarterly. I review books on digital humanities in libraries to extend the reach of the scholarship of my peers. I anticipate several upcoming conference talks and appearances to further develop my work on TEI pedagogy and musical genre in online information systems.
Service
My service is an extension of my librarianship and scholarship activity; I help to build community, capacity, and infrastructure in digital humanities, often at the interstices of music studies.
As part of my engagement with the global digital humanities community, I have sought service roles across disciplines that create opportunities for the cross-fertilization that I believe will enliven these fields. I am a founding member of Music Scholarship Online (MuSO), described above, for which I participated on an international team to crosswalk metadata for eighteenth-century music objects from Europeana, the EU digital platform for cultural heritage, to the music-specific data model developed for MuSO. For three years in a row, I have served as a member of the international program committee for the Conference on Digital Libraries for Musicology, a cross-disciplinary presentation venue for researchers working on, and with, large-scale digital libraries and databases in the domain of music and musicology. I have worked on advisory committees for grant-funded projects at Big Ten institutions supporting the creation of a computational text analysis curriculum for academic librarians (“Digging Deeper, Reaching Further”) and the development of a data capsule appliance for non-consumptive research on the copyrighted corpus in the HathiTrust Digital Library. I write peer reviews for the major national and international digital humanities conferences, as well as for several serial publications on digital libraries and music librarianship, and I have served on a review committee for the National Endowment for the Humanities Office of Digital Humanities. My editorial role with the Nimble Tents Toolkit, directly related to the mapathons described earlier, involves reviewing new contributions on the organization of rapid response teams and grassroots events to address urgent climate and political challenges involving free or widely used digital tools and platforms.
As part of my ongoing involvement in the Music Library Association (MLA), I have helped plan and organize several pre- and post-conference activities involving a range of hands-on trainings and presentations in digital methods at the annual meetings. One of my workshops, “A Workshop on Maps & Timelines,” which I subsequently published online, has been highlighted on the website of the Stanford Humanities + Design lab as a testimonial of their software application, Palladio. I have served on the MLA Emerging Technologies and Services Committee, and as the current convener of the Digital Humanities Interest Group, I have led an effort to create a comprehensive list of digital libraries, digital archives, open datasets, and digital humanities projects in music.
My involvement as a steering committee member of the Rutgers Digital Humanities Initiative (DHI) has been a focal point of my local service activity. As the only librarian on the steering committee, my work with the DHI is discipline-neutral, and involves building a research community through the gathering, synthesis and dissemination of information on key events, lectures, conferences, and opportunities available at Rutgers and in the Greater New York area. In addition to organizing local workshops, many of which I also led, I have also planned lectures, open house events, and an annual symposium showcasing the digital humanities research of students and faculty at Rutgers and at member institutions of the New Jersey Digital Humanities Consortium. I ensure that materials from all workshops are archived and freely available online. These materials continue to generate interest well after the date of the event; one of the most visited pages (700 unique page views) of the Rutgers DHI website is the workshop I developed on “Thematic Maps in QGIS.” In addition, I have served on an interdisciplinary review committee for the award of digital humanities seed grants, funded by the Rutgers School of Arts and Sciences, to support the early stages of digital project work by Rutgers graduate students and faculty. This committee disbursed grants to ten recipients, whose work is presented at the annual symposium (“DH Showcase”) and on the DHI’s website.
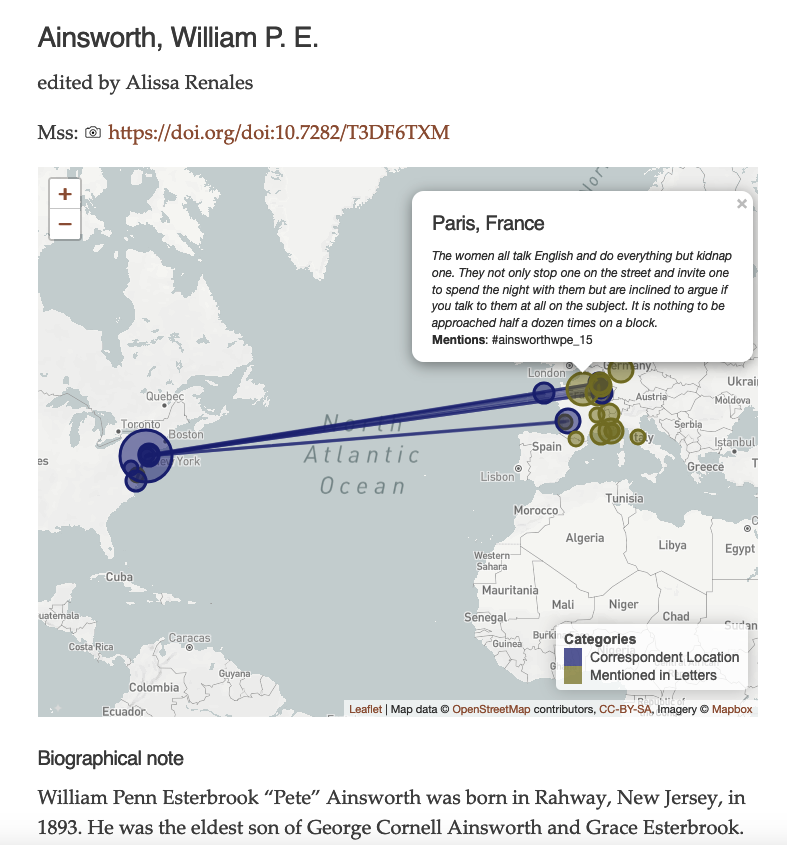
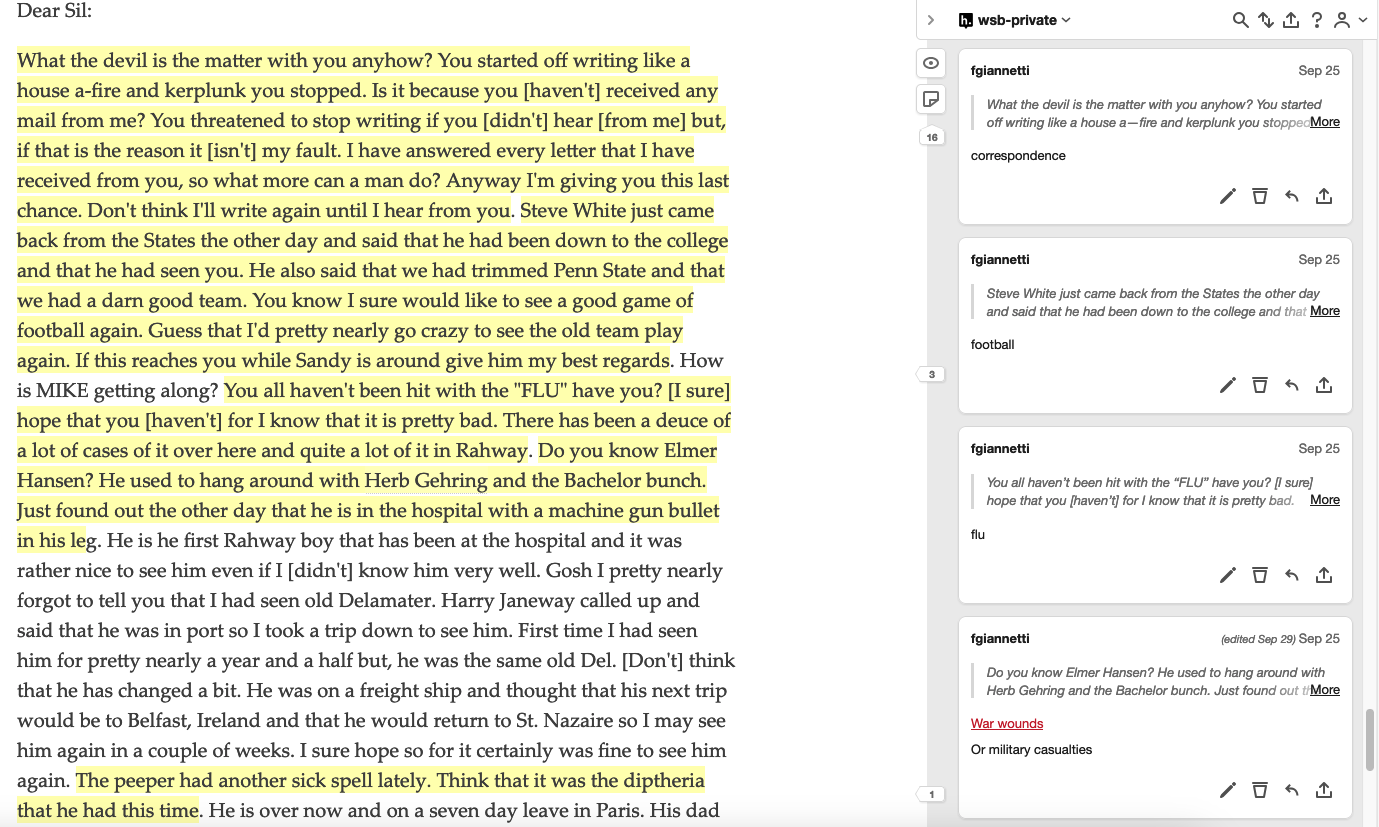
I take pleasure in mentoring and advising students working with digital methods. I have worked with Rutgers Future Scholars and Aresty Research Assistants on projects relating to text encoding and digital editions of correspondence collections. I also served on the Research Database Task Force, which examined ways of expanding and promoting undergraduate research opportunities at Rutgers–New Brunswick.
Conclusion
As a digital humanities librarian with subject liaison responsibilities, I have sought to emphasize the commonalities of digital research methods with longstanding humanistic scholarship practices to transform teaching, learning, and research in a range of disciplines. Due to my interventions in pedagogy and outreach, I have helped to establish the Libraries as one of very few places at Rutgers for students and faculty to develop technical skills that are rarely taught in academic units. I have promoted the use of unique library collections and computational methods of analysis among scholars and students, and I have demonstrated their significance in peer-reviewed publications and presentations. I look forward to contributing to the ongoing transformation of library and humanistic practices at Rutgers University, among library professionals and researchers locally and globally in the years to come.
]]>