Note added March 3, 2015 – Beth Plale of Indiana University kindly offered me the following corrections on my account of the Data Capsule. The Data API is in fact only available in Secure Mode. I think in my struggle to learn how to use the Data Capsule, it got a bit muddled in my mind when I was in Secure versus Maintenance Mode. She explained the difference as follows:
Maintenance mode is where you upload tools and external data from your desktop or the web. You are at this point installing everything you need to do analysis. The Data API is not available in maintenance mode. Solr API is available in maintenance mode.
Secure mode: once you have external data and tools loaded into VM, switch to secure mode where your scripts run to download texts through the Data API, your analysis tools run, then you store results to a special directory that allows you to get derived results out of the VM. The Solr API is available in secure mode too.
This is a lightly adapted version of a talk I gave in Alexander Library on February 24, 2015. My charge was to describe the HathiTrust Research Center, explore the opportunities it provides to the user public, and imagine how we (Rutgers librarians) might work with our users to take best advantage of those opportunities.
Just the Facts
The HathiTrust Research Center is collaboration between Indiana University, the University of Illinois at Urbana-Champaign, and the HathiTrust Digital Library. It was established in 2011 to enable computational research across the HathiTrust’s vast collection of published works.
The HTRC has been conceived with the digital humanities researcher in mind. The research tools that the HTRC has been engaged in developing aim to surmount some of the technical and logistic challenges inherent to large-scale text analysis. In addition, these tools support algorithmic analyses even when copyright restrictions preclude human-reading level (“consumptive”) access to the text.
HTRC Portal
The HTRC portal is separate from the HathiTrust Digital Library interface and requires the creation of an individual user account. The tools and infrastructure of the HTRC are free and open to all researchers (being affiliated with a HathiTrust partner organization has no bearing on your ability to use it).1
HTRC Portal
From the HTRC portal (sometimes called the production stack in the HTRC documentation), there are two main services: the Workset Builder and Algorithms.
The Workset Builder is a search interface for the HathiTrust public domain corpus (2.7 million volumes). Search results can be saved as a workset, or in other words, a digital study carrel in which you amass a collection of volumes of particular interest to you. Worksets can be made public or private, with the understanding that public worksets can be reused by any HTRC member. The workset is also a means of constraining your data set, so that you perform analyses only on the material of relevance to you.
The algorithms currently offered through the HTRC portal include, on the simpler end, term frequencies and word clouds, and on the more complex end, named entity extraction (person, location, organization, etc.), LDA topic modeling, and Dunning log likelihood, which can be used to compare and contrast two different worksets. When you apply an algorithm to a workset, it becomes a job, and can be monitored for status and results on the Results page. Harriet Green and Sayan Bhattacharyya, both of UIUC, prepared this wonderful handout listing and describing the HTRC portal algorithms.

HTRC Sandbox
In addition to HTRC portal, there is a sandbox stack with the same tools, intended to help scholars build and test algorithms. The sandbox runs against the non-Google digitized content (250,000 volumes). The advantage of the sandbox is that the Solr index and HTRC Data API can be accessed directly, permitting the use of the researcher’s algorithms.
Bookworm
Currently on the sandbox stack is the HTRC instance of Bookworm. Bookworm is a Culturomics project that is co-directed by Ben Schmidt (Northeastern University) and Erez Aiden (Rice University). Loosely based on the Google Ngram viewer, Bookworm’s browser interface provides a time series view into text corpora that encourages the exploration of large-scale trends. The HTRC’s implementation of Bookworm certainly counts among its most user friendly tools, which is perhaps why Stephen Downie of UIUC recommended it as the first step of a digital pedagogy workflow in a recent poster presentation. Although still a prototype over 250,000 volumes, its interactivity and metadata facets make the HTRC Bookworm quite useful for hypothesis forming.
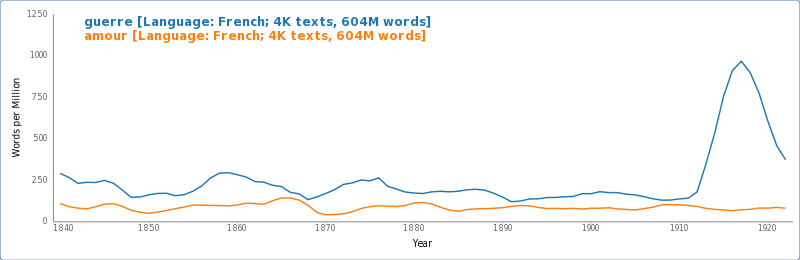
Extracted Features
The Extracted Features dataset is also available on the sandbox for use by scholars. At present, this dataset contains a select set of page-level features extracted from the 250,000 non-Google-digitized public domain volumes. Conceptualized as a non-consumptive analysis tool, the Extracted Features dataset will likely grow to include a much larger subset of HathiTrust volumes.
Pre-extracted features save the researcher much time and effort, since the pre-analysis, including tokenization, part-of-speech tagging, hyphenation rejoining and header/footer recognition, is already performed.
HTRC Data Capsule
The HTRC Data Capsule permits “non-consumptive” research on HathiTrust’s use protected texts (works in copyright). What is non-consumptive research? As defined by the Google Books settlement: “research in which computational analysis is performed on one or more books, but not research in which a researcher reads or displays.”
The HTRC Data Capsule is currently available through the main portal, but requires another set of login credentials. It works by giving you your own virtual machine (VM) that runs within the HTRC domain. You can configure that VM as you would your own desktop with your tools, although a number of these tools (R, Python) were pre-installed when I gave it a try. There are two modes of operation for the VM: Maintenance and Secure. In my experience, I needed to be in Maintenance Mode in order to have network access and query both the Solr index and the Data API. You would then need to switch to Secure Mode, in which network and other data channels are restricted, in order to have the results of your analysis e-mailed to you. A detailed tutorial on how to set up and interact with the VM, as well as four use cases, is available on the HTRC wiki.
I find the Data Capsule to be among the most exciting and potentially game-changing tools of the HTRC. At the risk of appearing slightly provincial, I will also go ahead and say that I find it difficult to use. This is one area in particular where I am looking forward to meeting the HTRC UnCampers next month, with whom I can ask questions and put forth areas of difficulty.
To give you an idea of the challenges, before analyzing a text, you first need to procure the volume IDs of the volumes you wish to analyze. You do this by querying the Solr API with a URL encoded string in the VM’s provided browser. Here is a sample query that will look for everything that has the word “fate” in the title and return only the first 20 results:
http://chinkapin.pti.indiana.edu:9994/solr/meta/select/?q=title:fate&rows=20
Right now you can query either the OCRed text or the MARC metadata fields (in my experience, the latter works more efficiently). Another difficulty I found was that I could not get keyboard shortcuts to work in the VM, meaning that I had to type out these URLs manually, which probably accounted for at least some of the 400 (“bad request”) error messages I received. The Solr API returns MARC XML records, which you then sift through in order to find the desired volume IDs.
Next, you might want to query the Data API in order to access the content of those volumes. My little Project Gutenberg experience of computational analysis has not adequately prepared me for the task of calling a data API within an R or Python script, so here I was very grateful for the sample scripts provided on the VM.
I followed the use case on feature extraction using the Feature API, which once again required expressing the query in URL encoding. A sample query to run in the browser of the VM for this specific API:
http://chinkapin.pti.indiana.edu:9447/feature-api/tdm?volumeIDs=inu.3011012|uc2.ark%3A%2F13960%2Ft2qxv15&dict=true
Here, be mindful that the raw volume IDs retrieved from the Solr API need to be separated by a pipe character. Some special characters may need to be expressed in URL encoding, which is to say that colons become %3A and forward slashes become %2F. My hope is to spare you a few rounds of 400 errors… Next, I ran the R analysis on the derived features data, which produces a series of visualizations that will be familiar to any users of the R graphics packages (e.g. a word cloud, a histogram, a word frequency distribution, a scatter plot, etc.). Lastly, you’ll need to switch to Secure Mode to e-mail yourself a link to download your visualizations.
Other HTRC Affiliated Research Initiatives
The NovelTM partnership seeks to produce the first large-scale cross-cultural study of the novel using quantitative methods.
The Single Interface for Music Score Searching and Analysis project (SIMSSA) uses machine learning to enable the search and analysis of musical scores in much the same way we currently search for words in text documents. SIMSSA researchers use Optical Music Recognition (OMR) software to transform digital images of music into searchable representations of music notation.
Workset Creation for Scholarly Analysis: An immediate objective for HTRC is to allow scholars to collect items together for large-scale computational analysis. But the print-based metadata inherited by the HathiTrust was conceived to allow researchers to find books in a building. It does not support the granularity of sorting and work selection that scholars now expect. A goal of Worksets is to enrich the metadata in HathiTrust and augment it with URIs to leverage discovery and sharing through external services.
How to get involved
The HTRC maintains several listservs, of which I want to mention htrc-announce-l for announcements about workshops, new tools and larger community issues, and htrc-usergroup-l for technical discussions.
You can also now register for the third annual HTRC UnCamp on March 30-31, 2015 at the University of Michigan in Ann Arbor. I’ve signed up, and I’d love to see some familiar faces!
The UnCamp is part hands-on coding and demonstration, part inspirational use-cases, part community building, and a part informational, all structured in the dynamic setting of an un-conference programming format.
Future directions…
So here are a few ideas to introduce the HTRC to the Rutgers (digital) humanities community. At the smaller end, I can conceive of an HTRC LibGuide and/or a web tutorial on how to build a workset and perform computational analyses on that workset using the pre-existing algorithms. An in person workshop on the HTRC portal tools and the Data Capsule would be beneficial to our graduate students and faculty. Perhaps something like what Harriett Green and Sayan Bhattacharyya did with their Savvy Researcher workshop. Although I would reserve my involvement for after my initiation into all things HTRC at the upcoming UnCamp. At the more complex end of the spectrum, perhaps the Rutgers University Libraries could host hackathon night in which researchers create custom scripts to test in the Data Capsule. Or create a Bookworm of a subset of the Edison Digital Edition (even if Bookworm is not really an HTRC project)? I’ll be polling you for your needs and opinions…
Further Reading
Resources and Guides
HathiTrust Research Center Wiki. HathiTrust Research Community Pages. https://wiki.htrc.illinois.edu/display/COM/HathiTrust+Research+Community+Pages.
University Library, University of Illinois at Urbana Champaign. Introduction to HathiTrust Research Center. http://uiuc.libguides.com/htrcguide.
Publications and Presentations
HathiTrust Research Center Wiki. HTRC Publications, Presentations. https://wiki.htrc.illinois.edu/display/OUT/HTRC+Publications%2C+Presentations.
1. Jeremy York, Assistant Director of the HathiTrust Digital Library, later clarified for me that the proposals of researchers affiliated with HathiTrust partner institutions do receive preferential attention in the HTRC’s Advanced Collaborative Support RFP process.
Comments